Application Research, AI+X
Abstract
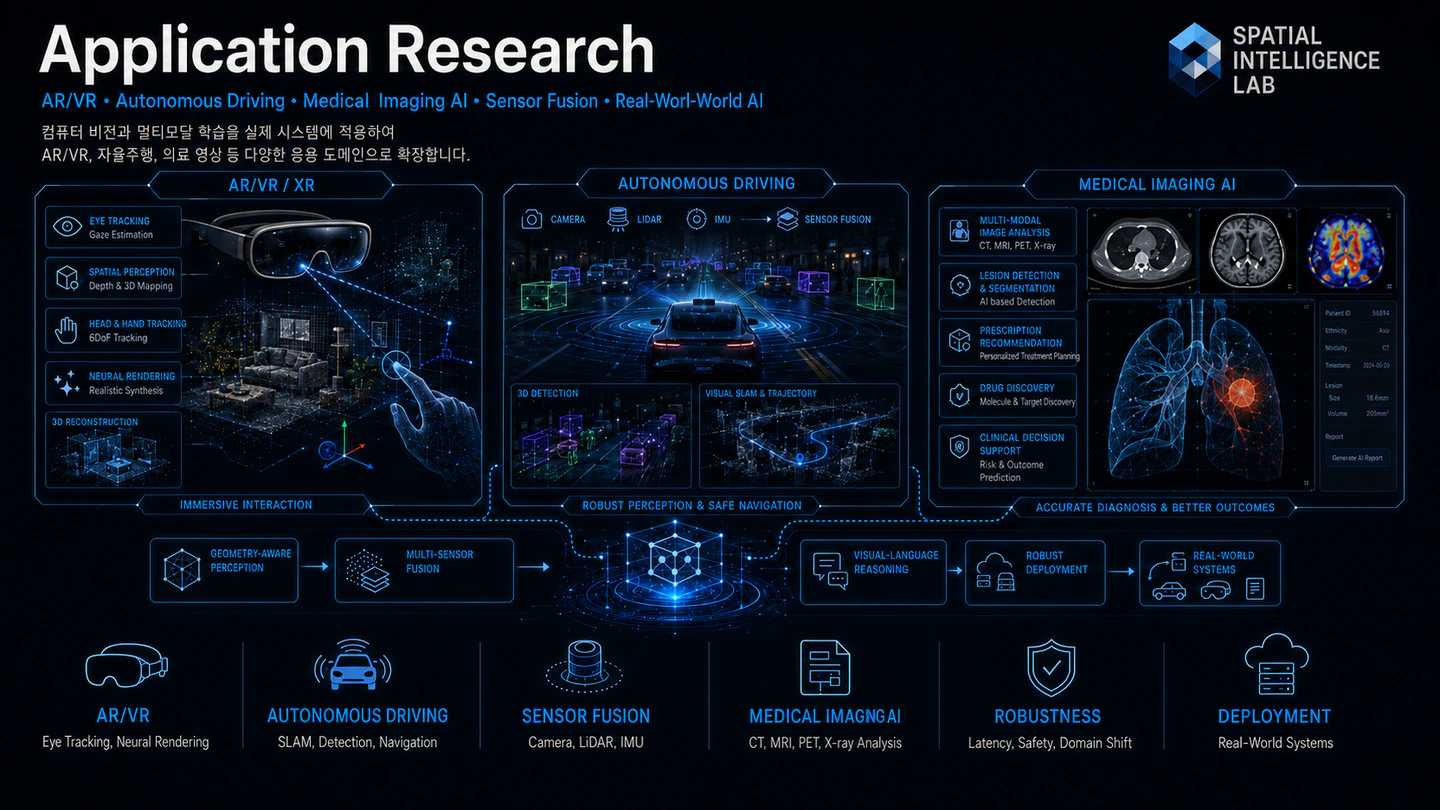
Our application-oriented research asks how perception, geometry, and multi-modal reasoning can be transformed from offline benchmarks into systems that operate reliably in the physical world. We treat spatial intelligence as a shared core engine and pursue AI+X collaborations with domain experts across many verticals, including head-mounted displays, driving platforms, clinical workstations, civil and urban systems, and biology labs. Despite rapid progress on academic leaderboards, deployed settings still struggle with latency budgets, long-tail conditions, sensor heterogeneity, and safety constraints that benchmark accuracy alone cannot capture. Our group studies on-device spatial perception for AR/VR, planning-aware perception and occupancy world models for autonomous driving, trustworthy 3D segmentation for medical imaging, spatio-temporal and foundation-model forecasting for transportation and construction demand, and 3D vision for animal behavior, all sharing a backbone of multi-sensor fusion across camera, LiDAR, depth, and IMU. We treat robustness, calibration, and domain shift as first-class objectives rather than afterthoughts. The broader vision is a unified spatial-intelligence stack that lets the same geometric and semantic priors travel across consumer XR, mobility, healthcare, civil infrastructure, and the long tail of non-human subjects.
Research Idea
We position spatial intelligence as the core engine of our group and work in close partnership with domain experts on AI+X projects. Our role is to bring perception, geometry, and multi-modal reasoning; our collaborators bring the application context, the data, and the questions that matter in their fields, spanning AR/VR, autonomous driving, medical imaging, transportation and construction demand forecasting, and animal behavior. Each subsection below corresponds to one of those verticals, and we are actively looking for students and collaborators in all of them.
AR/VR: On-Device Spatial Perception and Neural Rendering
Mixed-reality headsets and smart glasses are becoming the next computing platform, and they demand a spatial stack that runs entirely on-device: meters-accurate tracking, photoreal rendering, eye-aware interfaces, and scene understanding that survives motion blur and aggressive viewpoint change. We explore how 3D Gaussian Splatting, neural fields, and structured scene representations can be compressed and accelerated for real-time SLAM and novel-view synthesis on power-budgeted hardware.
We are particularly interested in coupling eye tracking and gaze priors with geometric reconstruction, using where the user looks to drive foveated rendering, attention-conditioned scene parsing, and adaptive level of detail. Our long-term goal is a headset that reconstructs and understands a new room in seconds and behaves predictably the next time the user walks in.
Selected references
- SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAM (Keetha et al., CVPR 2024): https://arxiv.org/abs/2312.02126
- Gaussian Splatting SLAM (Matsuki et al., CVPR 2024): https://arxiv.org/abs/2312.06741
- Project Aria: A New Tool for Egocentric Multi-Modal AI Research (Meta Reality Labs, 2023+): https://arxiv.org/abs/2308.13561
- Nymeria: Multimodal Egocentric Daily Motion in the Wild (Ma et al., 2024): https://arxiv.org/abs/2406.09905
- TaoAvatar: Full-Body Talking Avatar for AR Devices via 3DGS (2025): https://arxiv.org/abs/2510.13978
Autonomous Driving: Planning-Oriented Perception and Occupancy World Models
The center panel of the figure, the car surrounded by sensor cones and a BEV grid, captures a key open problem: how do we move past task-isolated perception toward representations that serve planning? We study end-to-end and modular driving stacks that share a single bird’s-eye-view or 3D-occupancy backbone across detection, mapping, motion forecasting, and trajectory planning, so that downstream uncertainty propagates cleanly back into upstream features.
A second thread is occupancy-based world models: forecasting how the surrounding 3D scene evolves, not just where current objects are. We are also interested in vision-language interfaces for driving, including graph and chain-of-thought reasoning grounded in scene tokens, so that future driving stacks are auditable, queryable, and able to handle corner cases the data distribution never contained.
Selected references
- Planning-oriented Autonomous Driving (UniAD) (Hu et al., CVPR 2023 Best Paper): https://arxiv.org/abs/2212.10156
- OccWorld: Learning a 3D Occupancy World Model for Autonomous Driving (Zheng et al., ECCV 2024): https://arxiv.org/abs/2311.16038
- DriveLM: Driving with Graph Visual Question Answering (Sima et al., ECCV 2024 Oral): https://arxiv.org/abs/2312.14150
- DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models (Tian et al., 2024): https://arxiv.org/abs/2402.12289
- LMDrive: Closed-Loop End-to-End Driving with Large Language Models (Shao et al., CVPR 2024): https://openaccess.thecvf.com/content/CVPR2024/papers/Shao_LMDrive_Closed-Loop_End-to-End_Driving_with_Large_Language_Models_CVPR_2024_paper.pdf
Medical Imaging AI: Trustworthy 3D Segmentation and Foundation Models
The right panel of the figure, with CT, MRI, PET, and X-ray volumes, points to a domain where accuracy is not optional and where models must transfer across scanners, protocols, and patient populations. We study 3D segmentation and detection pipelines that build on the strongest open backbones (the nnU-Net family and SAM-style foundation models for medical images), and we focus on the parts of the problem that most often break in clinical practice: domain shift, calibration, federated training across hospitals, and segmentation of long-tail anatomy.
Our research interest is in making these models honest, well-calibrated, uncertainty-aware, and able to flag out-of-distribution scans rather than hallucinate a confident mask. We welcome collaboration with radiology and clinical partners who want to take vision research from the leaderboard to the reading room.
Selected references
- Segment Anything in Medical Images (MedSAM) (Ma et al., Nature Communications 2024): https://www.nature.com/articles/s41467-024-44824-z
- MedSAM2: Segment Anything in 3D Medical Images and Videos (Ma et al., 2025): https://arxiv.org/abs/2504.03600
- nnU-Net Revisited: A Call for Rigorous Validation in 3D Medical Image Segmentation (Isensee et al., 2024): https://arxiv.org/abs/2404.09556
- FLARE: A Federated Learning Approach to Robust nnU-Net Training Across Multi-Center Abdominal CT (Ma et al., 2024): https://arxiv.org/abs/2308.05862
Sensor Fusion and Real-World Robustness
Cutting across all three pillars is the bottom row of the figure: camera + LiDAR + IMU fusion, robustness to latency, safety, and domain shift, and deployment in real-world systems. We treat sensor fusion as a unifying lens, the same geometric and uncertainty-aware machinery that aligns multi-camera rigs in a headset also aligns LiDAR and cameras on a vehicle, and the same domain-shift tools that protect a driving stack at night protect a segmentation model on a new scanner.
If you are excited about pushing spatial AI all the way from a research notebook to a device a user actually wears, drives, or scans with, we would love to hear from you.
Selected references
- Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives (Grauman et al., CVPR 2024): https://ego-exo4d-data.org/
- Aria Everyday Activities Dataset (Lv et al., 2024): https://arxiv.org/abs/2402.13349
- A Survey on Occupancy Perception for Autonomous Driving (Information Fusion, 2025): https://github.com/HuaiyuanXu/3D-Occupancy-Perception
Transportation and Construction Demand Forecasting
A growing thread of our AI+X work happens with civil-engineering and urban-systems collaborators who study transportation networks, construction projects, and supply chains. Together we are exploring how spatial AI, spatio-temporal graph models, and time-series foundation models can be applied to demand forecasting at city scale, from passenger and freight flow on a road or rail network, to ridership at individual stations, to project demand and material or supply-chain volumes for construction. The lab does not yet have published work in this vertical, so we approach it as an open direction rather than a claim of prior expertise.
What makes this collaboration productive is access to real-world data through our partners (operator logs, sensor feeds, project pipelines, regional statistics) paired with our experience in building large foundation models that ingest heterogeneous, multimodal signals. We are interested in zero-shot and few-shot forecasting, in spatial graph structure that respects the underlying transportation or supply network, and in calibrated uncertainty for decisions that affect schedules, budgets, and infrastructure.
Selected references
- A decoder-only foundation model for time-series forecasting (TimesFM) (Das et al., ICML 2024): https://arxiv.org/abs/2310.10688
- Chronos: Learning the Language of Time Series (Ansari et al., TMLR 2024): https://arxiv.org/abs/2403.07815
- STAEformer: Spatio-Temporal Adaptive Embedding Makes Vanilla Transformer SOTA for Traffic Forecasting (Liu et al., CIKM 2023): https://arxiv.org/abs/2308.10425
- PDFormer: Propagation Delay-Aware Dynamic Long-Range Transformer for Traffic Flow Prediction (Jiang et al., AAAI 2023): https://arxiv.org/abs/2301.07945
Animal Behavior and Pose Estimation
A second AI+X direction takes the lab’s spatial-intelligence toolbox (equivariance, feed-forward 3D foundation models, multi-view geometry, sparse correspondence matching) and applies it to non-human subjects, with a particular focus on avian species, especially migratory shorebirds and waterfowl, endangered raptors, regional endemics across the East Asian–Australasian Flyway, and the long tail of bird diversity that conventional human-centric models almost never see. The work also extends to mammals and other taxa where the same geometric and category-aware ideas transfer. We partner with neuroscience, ecology, and wildlife collaborators in settings where labeled data is scarce, viewpoints are extreme (overhead camera traps, fisheye enclosures, telephoto wildlife footage), articulation is highly dexterous, and appearance shifts wildly between species. These are exactly the regimes in which generic human-centric pose and reconstruction models break, and where category-aware, equivariant, and few-shot methods earn their keep.
We are particularly excited about feed-forward animal reconstruction from casual video, family-aware shape and pose estimation across taxa, and 3D Gaussian-splatting style models that can quantify pose and appearance for longitudinal behavior studies. This direction connects naturally with the broader CV4Animals workshop community, with whom we share the goal of making 3D vision tools usable by biologists, not just ML researchers.
Selected references
- CV4Animals Workshop (CVPR workshop series): https://www.cv4animals.com/
- Learning the 3D Fauna of the Web (Li, Litvak, Li, Zhang, Jakab, Rupprecht, Wu, Vedaldi, Wu, CVPR 2024): https://arxiv.org/abs/2401.02400
- AniMer: Animal Pose and Shape Estimation Using Family Aware Transformer (Lyu, Zhu, Gu, Lin, Cheng, Liu, Tang, An, CVPR 2025): https://arxiv.org/abs/2412.00837
- Animal Avatars: Reconstructing Animatable 3D Animals from Casual Videos (Sabathier, Mitra, Novotny, ECCV 2024 Oral): https://arxiv.org/abs/2403.17103
- Pose Splatter: A 3D Gaussian Splatting Model for Quantifying Animal Pose and Appearance (NeurIPS 2025): https://arxiv.org/abs/2505.18342
Jongmin Lee
Assistant Professor of Computer Science Engineering
My research focuses on computer vision and machine learning, with interests in visual geometry, 3D vision, and spatial reasoning with multi-modal LLMs. I explore applications in autonomous systems, AR/VR, robotics, and physical AI.