3D Visual Foundation Models
Abstract
Our research asks a single question. Can a neural network look at a handful of unposed images and immediately understand the 3D world they depict? Classical pipelines tackle this through long chains of feature matching, structure-from-motion, multi-view stereo, and per-scene optimisation, with each step accumulating error and brittleness when generalised beyond curated benchmarks. We study a new generation of 3D visual foundation models, feed-forward transformers that jointly predict camera parameters, dense point maps, correspondences, and renderable representations such as 3D Gaussians directly from pixels. Building on the DUSt3R, MASt3R, VGGT, and π³ line of work, we investigate stronger geometric inductive biases, permutation- and viewpoint-equivariance, dynamic-scene extensions, and unified outputs that bind geometry, appearance, semantics, and uncertainty. The longer-term vision is a single backbone that powers reconstruction, novel-view synthesis, object pose, and embodied perception, closing the loop between vision and the physical world.
Research Idea
3D visual foundation models are reshaping how machines perceive space. Instead of stitching together hand-crafted modules — keypoints, matchers, bundle adjusters, MVS — a single transformer now ingests raw, unposed images and outputs geometry, cameras, and correspondences in one forward pass. Our group works at the frontier of this shift. We are interested in students who want to redesign the architecture of 3D perception itself, not just train another head on top of a frozen backbone.
Feed-Forward 3D Reconstruction from Unposed Views
We explore models that take one, a few, or hundreds of images of an unseen scene and predict camera intrinsics, extrinsics, depth, and dense point maps in a single forward pass — no SfM, no per-scene optimisation, no calibration. This is the regime that DUSt3R opened and that VGGT and π³ have pushed to room-scale and beyond. The central technical questions we care about are: how do we scale these transformers to long input sequences while preserving multi-view consistency, how do we inject the right geometric inductive biases without sacrificing the elegance of pure attention, and how do we make predictions provably equivariant to view permutation and reference choice?
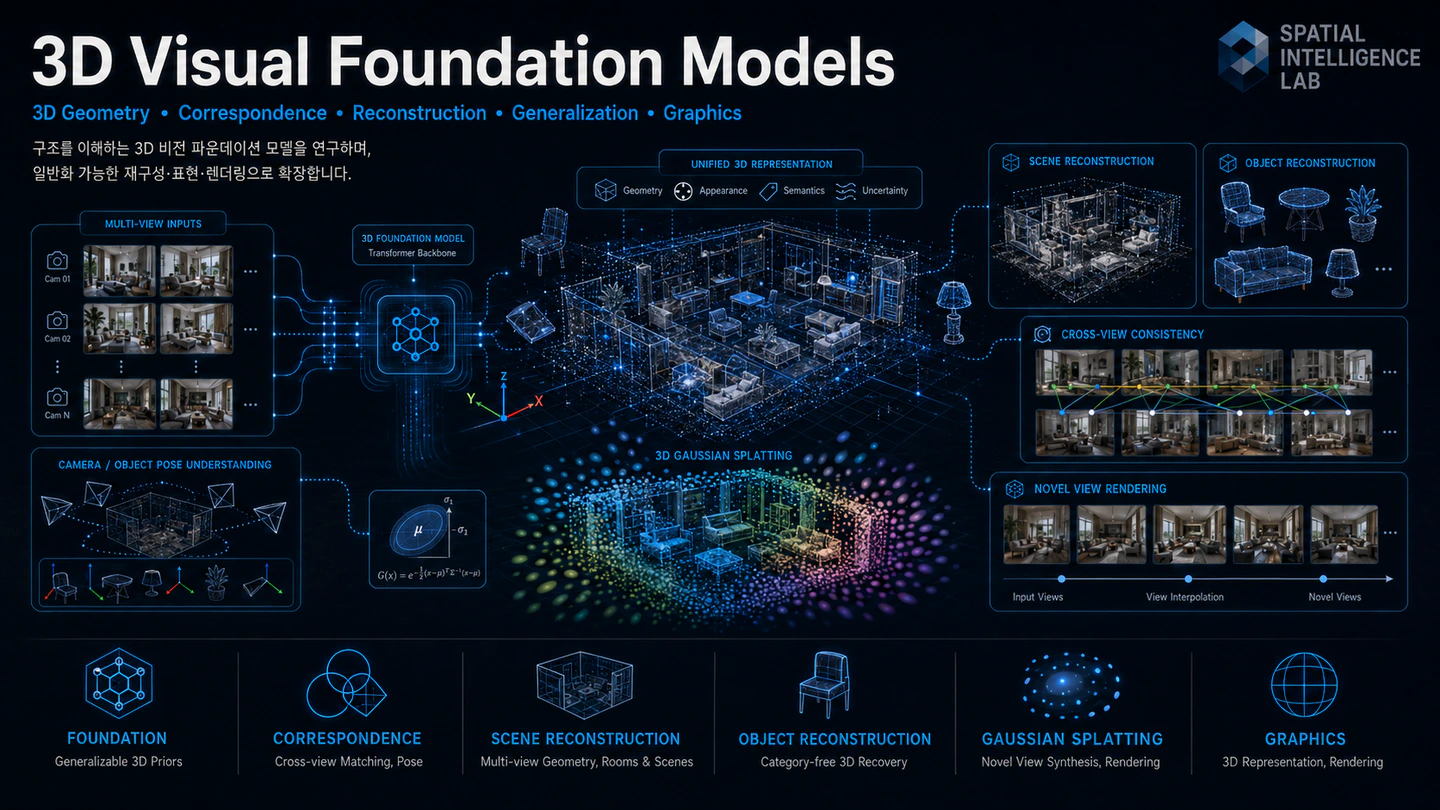
We treat the unified 3D representation (geometry + appearance + semantics + uncertainty) shown in the centre of our overview figure as the target output of a single backbone, rather than something assembled post-hoc.
Selected references
- VGGT: Visual Geometry Grounded Transformer (Wang et al., CVPR 2025 Best Paper) — https://arxiv.org/abs/2503.11651
- DUSt3R: Geometric 3D Vision Made Easy (Wang et al., CVPR 2024) — https://github.com/naver/dust3r
- π³: Permutation-Equivariant Visual Geometry Learning (Wang et al., 2025) — https://arxiv.org/abs/2507.13347
- MoGe: Monocular Geometry Estimation for Open-Domain Images (Wang et al., CVPR 2025 Oral) — https://arxiv.org/abs/2410.19115
- CroCo v2: Cross-View Completion Pre-training for Stereo and Flow (Weinzaepfel et al., ICCV 2023) — https://github.com/naver/croco
Dense Visual Correspondence at Foundation-Model Scale
Correspondence — knowing which pixel in image A maps to which point in image B and where that point sits in 3D — is the connective tissue of multi-view perception. The cross-view consistency grid on the right of our figure highlights this: the same object viewed from different angles must light up the same 3D location. We are interested in foundation models that learn correspondence as a consequence of solving 3D, rather than as an isolated descriptor task. This unlocks robust matching across extreme baselines, occlusion, and appearance change, and feeds directly into pose, SLAM, and re-identification.
We also study how correspondence-aware pretraining (CroCo-style cross-view completion, point-map regression with matching heads à la MASt3R) can be combined with semantic backbones such as DINOv2 to bridge geometry and recognition.
Selected references
- MASt3R: Grounding Image Matching in 3D (Leroy et al., ECCV 2024) — https://arxiv.org/abs/2406.09756
- MASt3R-SfM: Fully-Integrated Structure-from-Motion (Duisterhof et al., 2024) — https://arxiv.org/abs/2409.19152
- CroCo: Self-Supervised Cross-View Completion (Weinzaepfel et al., NeurIPS 2022) — https://github.com/naver/croco
- DINOv2: Learning Robust Visual Features without Supervision (Oquab et al., 2023) — https://github.com/facebookresearch/dinov2
Dynamic Scenes and 4D Foundation Models
The world moves. Most current 3D foundation models assume a rigid scene, but rooms, people, and objects rarely cooperate. We are interested in extending feed-forward 3D models to video — predicting time-varying point maps, segmenting dynamic from static structure, and recovering metric camera trajectories from completely uncalibrated footage. The “novel-view rendering” and “scene reconstruction” panels of our overview already implicitly assume this video-to-4D capability. Concretely, we explore how to scale dynamic point-map regression, fuse it with monocular geometry priors, and make video-pose pipelines reliable on in-the-wild internet clips, dashcams, and egocentric capture.
This direction is the bridge between offline 3D understanding and embodied, on-line spatial AI.
Selected references
- MonST3R: Estimating Geometry in the Presence of Motion (Zhang et al., ICLR 2025) — https://arxiv.org/abs/2410.03825
- MegaSaM: Accurate, Fast, and Robust Structure-and-Motion from Casual Dynamic Videos (Li et al., 2024) — https://mega-sam.github.io/
- ViPE: Video Pose Engine for 3D Geometric Perception (Huang et al., NVIDIA 2025) — https://arxiv.org/abs/2508.10934
- Dynamic Point Maps for Dynamic 3D Reconstruction (Sucar et al., 2025) — https://arxiv.org/abs/2503.16318
Renderable Representations and Downstream Spatial Reasoning
A reconstruction is only as useful as what you can do with it. We are interested in coupling 3D foundation backbones with renderable representations — 3D Gaussian splats, neural fields, mesh primitives — so that the same model can produce both metric geometry and photorealistic novel views (the rightmost slider in our figure). Downstream, this enables category-free object reconstruction, generalisable 6D object pose, and robotic manipulation from a single anchor view. We collaborate enthusiastically on the interface between foundation-model geometry and real-world tasks: SLAM, AR/VR, embodied agents, and digital twins.
If you are excited about either side — building the backbone, or pushing what becomes possible because the backbone exists — we would love to hear from you.
Selected references
- 3D Gaussian Splatting for Real-Time Radiance Field Rendering (Kerbl et al., SIGGRAPH 2023) — https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
- FoundationPose: Unified 6D Pose Estimation and Tracking of Novel Objects (Wen et al., CVPR 2024 Highlight) — https://arxiv.org/abs/2312.08344
- GigaPose: Fast and Robust Novel Object Pose Estimation via One Correspondence (Nguyen et al., CVPR 2024) — https://arxiv.org/abs/2311.14155
- MASt3R-SLAM: Real-Time Dense SLAM with 3D Reconstruction Priors (Murai et al., 2024) — https://arxiv.org/abs/2412.12392
Generative 3D Foundation Models: Steering Diffusion with 3D Priors
Once a backbone can read 3D out of pixels, the next question is whether it can also write 3D. Video and image diffusion models are spectacular at appearance, lighting, and motion, yet they hallucinate geometry; objects drift across frames, scales jitter, and camera trajectories are merely suggested rather than respected. 3D foundation models offer exactly the missing signal, supplying point maps, depth, and cross-view consistency that can be folded back into the generator. We are interested in this two-way street, where diffusion priors broaden what reconstruction can imagine and feed-forward 3D models keep what diffusion imagines geometrically honest.
Our anchor here is SteerX (ICCV 2025), which treats scene reconstruction as an inference-time steering signal for video diffusion. Geometric rewards computed from a pose-free feed-forward reconstructor (MEt3R / DUSt3R-style features) tilt the diffusion sampler toward samples whose multi-view geometry actually closes the loop, enabling camera-free image-to-3D, text-to-3D, and even 4D generation without retraining the base model. We see this as the prototype for a wider family of methods that splice 3D foundation backbones into generative pipelines: ReconX conditions a video diffusion model on a DUSt3R point cloud so that sparse-view reconstruction becomes temporal generation; ViewCrafter renders point-based clues to guide novel-view diffusion under explicit camera control; 3DGS-Enhancer uses 2D video diffusion priors to densify under-sampled Gaussian splats; and multi-view diffusion lines like MVDream (and SDS-style lifting) supply 3D-consistent training and distillation signals.
We are excited to push on the open questions in this space. How should geometric rewards be designed so that steering does not collapse diversity? Can we replace per-sample steering with light fine-tuning of diffusion backbones against 3D foundation models, so geometric consistency becomes a property of the prior rather than the sampler? And how far can this approach scale toward world-model-style generation that is, by construction, walkable, editable, and metrically correct? If you want to build generative 3D systems that are creative and geometrically grounded, this is where we would love to collaborate.
Selected references
- SteerX: Creating Any Camera-Free 3D and 4D Scenes with Geometric Steering (Park et al., ICCV 2025) — https://arxiv.org/abs/2503.12024
- ReconX: Reconstruct Any Scene from Sparse Views with Video Diffusion Model (Liu et al., 2024) — https://arxiv.org/abs/2408.16767
- ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis (Yu et al., TPAMI 2025) — https://arxiv.org/abs/2409.02048
- 3DGS-Enhancer: Enhancing Unbounded 3D Gaussian Splatting with View-consistent 2D Diffusion Priors (Liu et al., NeurIPS 2024 Spotlight) — https://arxiv.org/abs/2410.16266
- MVDream: Multi-view Diffusion for 3D Generation (Shi et al., ICLR 2024) — https://arxiv.org/abs/2308.16512
Jongmin Lee
Assistant Professor of Computer Science Engineering
My research focuses on computer vision and machine learning, with interests in visual geometry, 3D vision, and spatial reasoning with multi-modal LLMs. I explore applications in autonomous systems, AR/VR, robotics, and physical AI.