Geometric Representation Learning
Abstract
Modern foundation models excel at semantics yet remain surprisingly fragile under the geometric transformations that govern the physical world, including rotations, scale changes, viewpoint shifts, and 3D rigid motions. The open question is how to bake these symmetry priors directly into representations rather than hoping data augmentation will recover them. Our research designs group-equivariant and self-supervised representation learning frameworks in which transformations of the input induce predictable, structured transformations of the feature space. We study invariance, equivariance, spherical and SO(3) harmonics, and symmetry-aware self-supervision as a single, unified toolkit. The downstream payoff is models that generalise from less data, behave consistently across viewpoints, and provide a geometrically grounded substrate for 3D perception, robotics, and multimodal AI.
Research Idea
Geometry is not a feature we tack on at the end of a pipeline; it is the language the world is written in. When a chair rotates, the pixels move in a structured way; when a camera shifts, every scene point transforms by the same rigid motion. We are interested in deep representations that respect these structures by construction, so that what the network learns about one viewpoint transfers automatically to all the others.
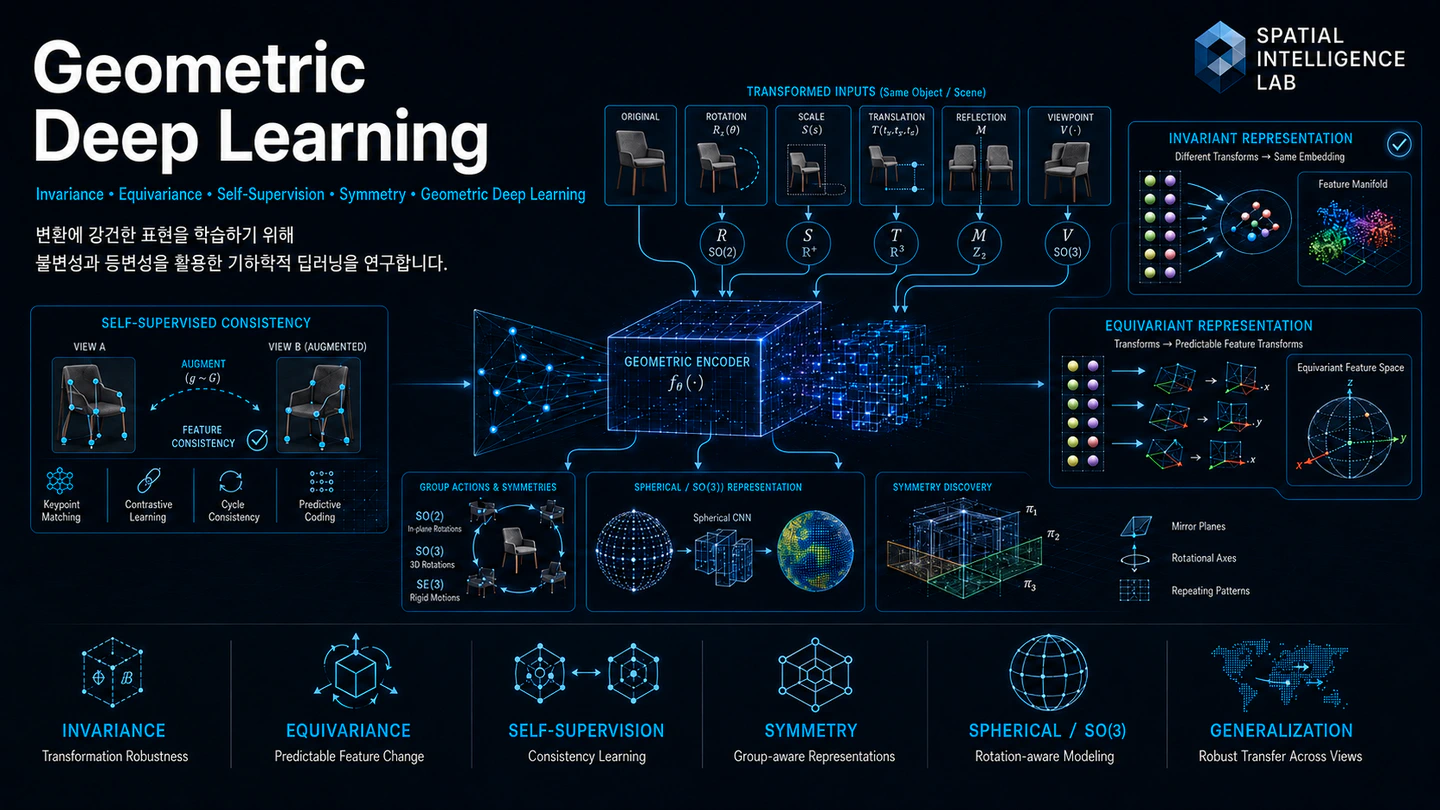
Concretely, we study four intertwined questions that the figure above tries to capture in one picture: when should a representation be invariant, when should it be equivariant, how do we supervise these properties without expensive labels, and how do we scale them up into modern transformer-based foundation models? If you find any of the threads below interesting, we would love to hear from you.
Invariance, Equivariance, and Symmetry as Inductive Bias
A good representation knows what to throw away and what to preserve. We treat invariance and equivariance as two halves of the same design principle: invariant features should ignore irrelevant transformations (a cat is still a cat upside down), while equivariant features should track the transformation so the geometry of the input survives in feature space. We are interested in group-equivariant convolutions and steerable architectures that hard-wire symmetries (rotation, reflection, scale, SE(2), SE(3)) into the layers themselves, as well as more flexible relaxations that learn approximate symmetries from data.
Recent work has shown that even very large transformers can be retrofitted with these priors, and we explore where the right trade-off lies between strict equivariance, soft equivariance, and architecture-agnostic symmetrisation.
Selected references
- Group Equivariant Convolutional Networks (Cohen & Welling, ICML 2016) — https://arxiv.org/abs/1602.07576
- General E(2)-Equivariant Steerable CNNs (e2cnn) (Weiler & Cesa, NeurIPS 2019) — https://arxiv.org/abs/1911.08251
- Learning Probabilistic Symmetrization for Architecture Agnostic Equivariance (Kim et al., NeurIPS 2023) — https://arxiv.org/abs/2306.02866
- Equivariant Neural Networks for General Linear Symmetries on Lie Algebras (Kim et al., 2025) — https://arxiv.org/abs/2510.22984
Spherical, SO(3), and Harmonic Representations for 3D
3D understanding is where geometric priors stop being a nice-to-have and start being essential. Pose, orientation, and viewpoint live on the rotation group SO(3), and naive Euclidean feature maps simply cannot represent them faithfully. We work with spherical CNNs, Wigner-D harmonic features, and SE(3)-equivariant transformers that operate in the frequency domain on the sphere, the same harmonic decomposition sketched on the right of the figure.
This direction connects directly to problems we care about: keypoint orientation, viewpoint estimation, point-cloud registration, and 3D pose regression. We are particularly interested in scaling these models to the size and data regimes of modern 3D foundation models while keeping their equivariance guarantees intact.
Selected references
- Spherical CNNs (Cohen et al., ICLR 2018) — https://arxiv.org/abs/1801.10130
- Learning SO(3) Equivariant Representations with Spherical CNNs (Esteves et al., ECCV 2018) — https://arxiv.org/abs/1711.06721
- Scalable and Equivariant Spherical CNNs by Discrete-Continuous (DISCO) Convolutions (Ocampo et al., ICLR 2023) — https://arxiv.org/abs/2209.13603
- SE3ET: SE(3)-Equivariant Transformer for Low-Overlap Point Cloud Registration (2024) — https://arxiv.org/abs/2407.16823
- EquAct: SE(3)-Equivariant Multi-Task Transformer for Robotic Manipulation (2025) — https://arxiv.org/abs/2505.21351
Self-Supervised Consistency and Generalisation
Strict equivariance is one way to get a structured feature space; learned consistency is the other. The left side of the figure (augmentation, contrastive learning, cycle consistency, predictive coding) is our second lever. We study self-supervised objectives that ask the network to produce features which transform predictably under known image and 3D operations, so the geometry emerges from the loss rather than the layer.
We are interested in how far this can be pushed: can a model trained only with symmetry-aware self-supervision match the data efficiency and robustness of architectures with built-in equivariance? And can the same recipe scale to large multimodal and 3D foundation models, giving us the robust transfer the bottom of the figure promises? These are open questions, and we welcome students who like to sit at the interface of theory, computer vision, and large-scale representation learning.
Selected references
- S-TREK: Sequential Translation and Rotation Equivariant Keypoints for Local Feature Extraction (Santellani et al., ICCV 2023) — https://arxiv.org/abs/2308.14598
- Understanding the Role of Equivariance in Self-supervised Learning (Wang et al., NeurIPS 2024) — https://arxiv.org/abs/2411.06508
- Improving Semantic Correspondence with Viewpoint-Guided Spherical Maps (Mariotti et al., CVPR 2024) — https://arxiv.org/abs/2312.13216
- Universal Few-shot Learning of Dense Prediction Tasks with Visual Token Matching (Kim et al., ICLR 2023) — https://arxiv.org/abs/2303.14969
- Axis-level Symmetry Detection with Group-equivariant Representation (Yu et al., ICCV 2025) — https://arxiv.org/abs/2508.10204
Equivariant Transformers and Steerable Foundation Models
The next frontier, and the upper-right corner of the figure, is asking whether the symmetry priors that worked beautifully for small group-equivariant CNNs can scale to the size, data, and architectures of modern foundation models. Transformers were not designed with rotation or SE(3) symmetry in mind, yet they now dominate large-scale 3D modelling, molecular simulation, and multimodal perception. The result is a fast-moving line of work on steerable and equivariant attention, where higher-degree spherical harmonics, Wigner-D representations, and Clebsch-Gordan tensor products are folded directly into the transformer block.
We are interested in two practical questions. First, how to design equivariant transformers that retain provable symmetry guarantees while matching the throughput and expressivity of plain ViTs. Second, how to use these architectures as foundation backbones for downstream geometric tasks (3D perception, robot manipulation, molecular property prediction) so that equivariance is inherited rather than re-engineered for each task.
Selected references
- EquiformerV2: Improved Equivariant Transformer for Scaling to Higher-Degree Representations (Liao et al., ICLR 2024) — https://arxiv.org/abs/2306.12059
- Steerable Transformers for Volumetric Data (Kundu & Kondor, 2024) — https://arxiv.org/abs/2405.15932
- Equivariant Spherical Transformer for Efficient Molecular Modeling (An et al., 2025) — https://arxiv.org/abs/2505.23086
- A Materials Foundation Model via Hybrid Invariant-Equivariant Architectures (Yan et al., 2025) — https://arxiv.org/abs/2503.05771
Jongmin Lee
Assistant Professor of Computer Science Engineering
My research focuses on computer vision and machine learning, with interests in visual geometry, 3D vision, and spatial reasoning with multi-modal LLMs. I explore applications in autonomous systems, AR/VR, robotics, and physical AI.