Fundamental Research - Invariance/Equivariance and Representation Learning
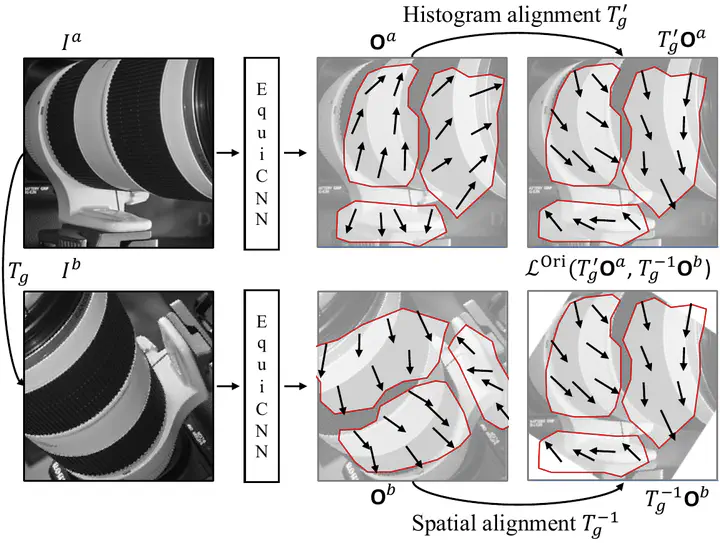 Image credit: REKD; CVPR 2022
Image credit: REKD; CVPR 2022Abstract: My fundamental research centers on developing representation learning frameworks that incorporate invariance and equivariance principles into modern deep learning systems. Invariance allows models to ignore irrelevant transformations (e.g., object rotation, scaling, lighting), while equivariance ensures that transformations in the input lead to predictable transformations in the representation. By embedding these mathematical structures into neural networks, we can build models that generalize better, require fewer labeled samples, and preserve geometric consistency. This line of research provides the theoretical and methodological foundations for robust perception, enabling downstream advances in computer vision, robotics, and multimodal AI.
Research Idea
In this line of research, we aim to design geometric deep learning (GDL) modules and representation learning frameworks that explicitly encode invariance and equivariance into neural architectures. Current foundation models capture high-level semantics but often lack geometric awareness, limiting their ability to reason about spatial structure and transformations.
To address this, we study group-equivariant neural networks and self-supervised learning approaches that enforce transformation consistency in the learned feature space. Our goal is to build models that not only recognize objects and scenes but also understand how they transform under rotations, reflections, translations, and scaling.
Relavant Papers:
3D Equivariant Pose Regression via Direct Wigner-D Harmonics Prediction, Jongmin Lee, Minsu Cho, NeurIPS 2024
Learning Rotation-Equivariant Features for Visual Correspondence, Jongmin Lee, Byungjin Kim, Seungwook Kim, Minsu Cho, CVPR 2023
Self-Supervised Equivariant Learning for Oriented Keypoint Detection, Jongmin Lee, Byungjin Kim, Minsu Cho, CVPR 2022
Self-supervised Learning of Image Scale and Orientation Estimation, Jongmin Lee, Yoonwoo Jeong, Minsu Cho, BMVC 2021
Group Equivariant Convolutional Networks, Cohen et al., ICLR 2016
Axis-level Symmetry Detection with Group-equivariant Representation, Yu et al., ICCV 2025
Learning Probabilistic Symmetrization for Architecture Agnostic Equivariance, Kim et al., NeurIPS 2023
Universal Few-shot Learning of Dense Prediction Tasks with Visual Token Matching, Kim et al., ICLR 2023
Extension of Spherical CNNs for object/scene representation (SO(3))
- Improving Semantic Correspondence with Viewpoint-Guided Spherical Maps (Mariotti et al., CVPR 2024)
- https://github.com/VICO-UoE/SphericalMaps
- Baselines
- Self-Supervised Viewpoint Learning From Image Collections (Mustikovela et al., CVPR 2020)
- ViewNet- Unsupervised Viewpoint Estimation from Conditional Generation (Mariotti et al., ICCV 2021)
- Spherical CNNs (Cohen et al., ICLR 2018)
- Learning SO(3) Equivariant Representations with Spherical CNNs (Esteve et al., ECCV 2018; series)
- SphereGlue: A Graph Neural Network based feature matching for high-resolution spherical images (Gava et al., CVPRW 2023)
Jongmin Lee
Assistant Professor of Computer Science Engineering
My research focuses on computer vision and machine learning, with interests in visual geometry, 3D vision, and spatial reasoning with multi-modal LLMs. I explore applications in autonomous systems, AR/VR, robotics, and physical AI.