Multi-Modal Large Language Models
Abstract
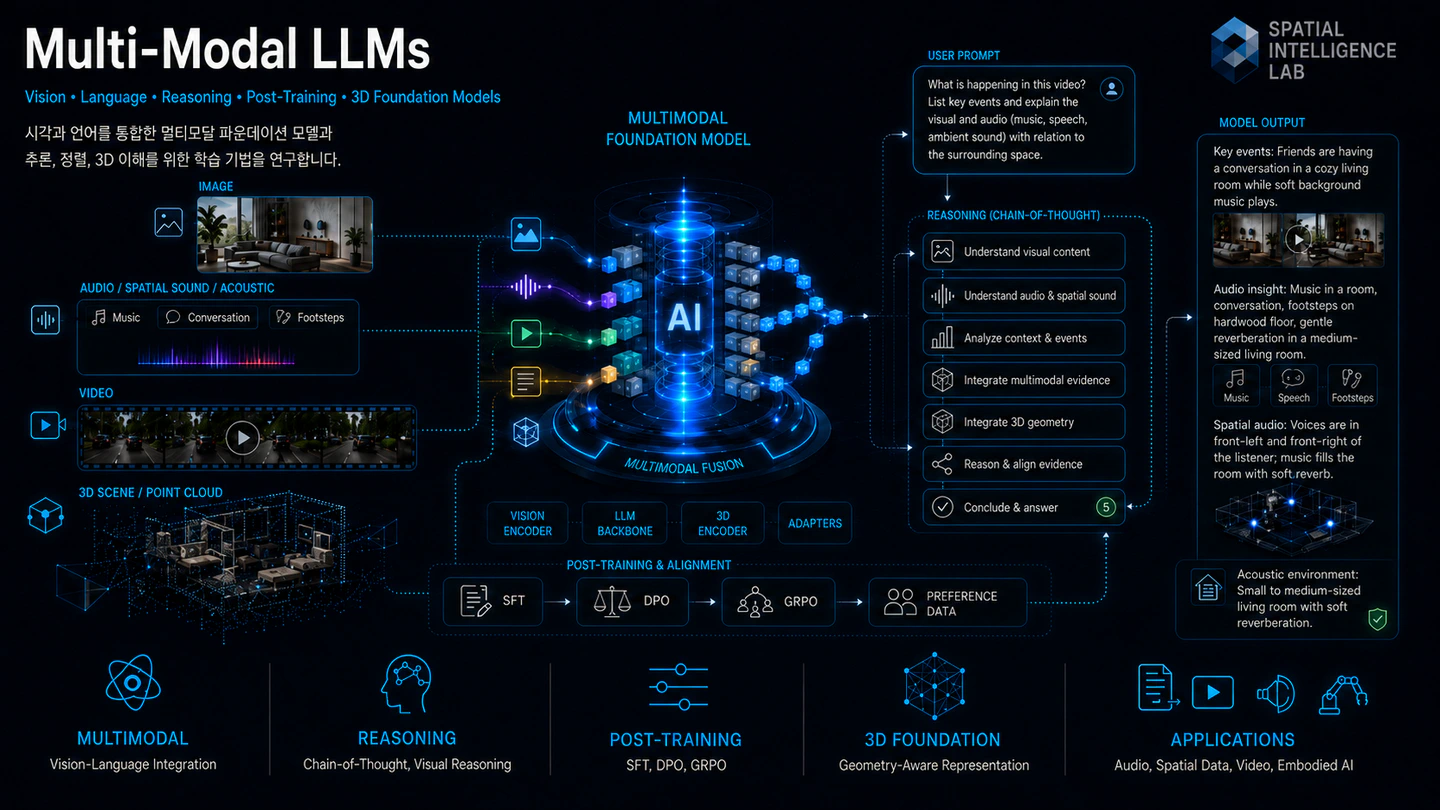
Our research asks how large language models can be taught to perceive, reason, and decide across the same rich mix of modalities (images, audio and speech, video, and 3D scenes) that humans handle effortlessly every day. Despite rapid progress, today’s multi-modal models still hallucinate fine-grained details, reason inconsistently over long audiovisual contexts, and lack the geometric grounding needed for embodied tasks. We tackle these gaps along four interlocking threads, namely building open multi-modal foundation models, eliciting reliable chain-of-thought reasoning that uses both pixel and acoustic evidence, designing post-training recipes that couple SFT with preference optimization (DPO, GRPO), and injecting 3D and geometry-aware representations into the multi-modal stack. Together, we aim to develop general-purpose systems that parse a noisy conversation as patiently as a careful listener, watch a long video without losing the thread, and walk through a 3D scene as confidently as a robot. The downstream payoff spans assistive listening, scientific discovery, embodied agents, and any setting where seeing, hearing, and reasoning must work in lockstep.
Research Idea
We organize our work into four threads that build on one another, and we love when students move between them. First, we lay the groundwork with open multi-modal foundation models — covering images, audio, video, and 3D — that the academic community can actually train and study. On top of that base, we teach models to reason over what they see and hear with chains of thought that genuinely use sensory evidence. We then shape their behavior through post-training, blending supervised fine-tuning with preference and reinforcement-learning recipes. Finally, we ground everything in 3D, so our models can eventually see, hear, reason, and act in the physical world.
Multi-Modal Foundation Models
At the center of our research sits the multi-modal foundation model — a single system that ingests images, speech and ambient sound, music, video, and 3D scenes and turns them into language, structure, or action. We are interested in how to build these models openly and efficiently, so that academic labs can still meaningfully participate in the frontier rather than only consume it. That means rethinking data curation, joint visual and audio tokenization, dynamic resolution and sample rates, and the bridge between vision and audio encoders and language backbones.
Concretely, we explore compute-efficient pre-training recipes (sub-1K GPU-hour regimes), high-quality instruction data spanning both visual and acoustic tasks, and architectures that scale gracefully from single-image and short-clip inputs to multi-image, long-video, and minutes-long audio. We are equally interested in the evaluation side: where current open multi-modal LLMs systematically break (multilingual speech, environmental sound in reverberant scenes, music understanding, audiovisual alignment), and what new benchmarks would actually move the field. We welcome students who want to ship open models and the data that powers them.
Selected references
- Qwen2.5-VL Technical Report (Bai et al., arXiv 2025) — https://arxiv.org/abs/2502.13923
- Qwen2.5-Omni Technical Report (Xu et al., arXiv 2025) — https://arxiv.org/abs/2503.20215
- Audio Flamingo 2: An Audio-Language Model with Long-Audio Understanding and Expert Reasoning Abilities (Ghosh et al., arXiv 2025) — https://arxiv.org/abs/2503.03983
- Molmo and PixMo: Open Weights and Open Data for State-of-the-Art VLMs (Deitke et al., CVPR 2025) — https://arxiv.org/abs/2409.17146
- Open-Qwen2VL: Compute-Efficient Pre-Training of Fully-Open MLLMs on Academic Resources (Wang et al., COLM 2025) — https://arxiv.org/abs/2504.00595
- LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training (Bo Li et al., arXiv 2025) — https://arxiv.org/abs/2509.23661
Visual Reasoning and Self-Correction
A foundation model is only as useful as the reasoning it can carry out on top of what it sees and hears. We are fascinated by sensory chain-of-thought — long, structured deliberation that genuinely uses pixel and acoustic evidence rather than papering over it with linguistic priors. Scientific figures, math diagrams, physical scenes, and noisy conversational audio all demand the same loop: look or listen, hypothesize, check, revise. The image at the top of this page deliberately shows that loop, including the moment the model says “Wait — potential failure of this reasoning step” and backtracks.
We explore how to elicit and verify this behavior: cold-start CoT data construction, process- versus outcome-level rewards, self-critique modules that catch the model’s own mistakes, and benchmarks that score how a model reasons, not just whether the final answer is right. We are especially interested in the open question of when visual reasoning genuinely transfers across domains.
Selected references
- Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models (Huang et al., arXiv 2025) — https://arxiv.org/abs/2503.06749
- Insight-V: Exploring Long-Chain Visual Reasoning with MLLMs (Dong et al., CVPR 2025 Highlight) — https://arxiv.org/abs/2411.14432
- Critic-V: VLM Critics Help Catch VLM Errors in Multimodal Reasoning (Zhang et al., CVPR 2025) — https://arxiv.org/abs/2411.18203
- VISCO: Benchmarking Fine-Grained Critique and Correction Towards Self-Improvement in Visual Reasoning (Wu et al., CVPR 2025) — https://arxiv.org/abs/2412.02172
- Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning LLMs (Chen et al., arXiv 2025) — https://arxiv.org/abs/2503.09567
Post-Training: SFT, DPO, and GRPO
Pre-training gets a multi-modal model to know things; post-training gets it to behave. We work across the full post-training stack — supervised fine-tuning, Direct Preference Optimization (DPO), and Group Relative Policy Optimization (GRPO) — to align VLMs with human preferences, factual grounding, and step-by-step correctness. Following the DeepSeek-R1 line of work, we are particularly drawn to rule-based and verifiable rewards that let RL training scale without expensive human labeling.
We are exploring how preference and reasoning objectives interact when the model has to attend to pixels and audio rather than text alone: how to design verifiable multi-modal rewards (e.g., grounding IoU, transcription word error rate, audio-event match), how to curate preference data that is actually informative for perception, and how to balance helpfulness with hard-won reasoning gains. Students with a taste for reinforcement learning and a stomach for messy training curves will feel at home here.
Selected references
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (DeepSeek-AI, arXiv 2025) — https://arxiv.org/abs/2501.12948
- Visual-RFT: Visual Reinforcement Fine-Tuning (Liu et al., ICCV 2025) — https://arxiv.org/abs/2503.01785
- Video-R1: Reinforcing Video Reasoning in MLLMs (Feng et al., NeurIPS 2025) — https://arxiv.org/abs/2503.21776
- Direct Preference Optimization: Your Language Model is Secretly a Reward Model (Rafailov et al., NeurIPS 2023) — https://arxiv.org/abs/2305.18290
- A Sober Look at Progress in Language Model Reasoning: Pitfalls and Paths to Reproducibility (Hochlehnert et al., arXiv 2025) — https://arxiv.org/abs/2504.07086
3D and Geometry-Aware Multi-Modal Understanding
Most VLMs treat the world as a flat grid of patches. But the scenes our models eventually have to act in — homes, labs, factories, streets — are emphatically three-dimensional. We are excited about pushing multi-modal LLMs from 2D pattern matching toward genuine 3D understanding: metric depth, object-level scene graphs, viewpoint consistency, and language that respects geometry.
We explore how to inject 3D inductive biases into otherwise standard VLM pipelines (depth plugins, 3D scene-graph supervision, point-cloud tokenizers), how to scale 3D vision-language data beyond the handful of curated indoor datasets, and how a 3D-grounded VLM can serve as the perception layer for embodied agents and robotics. This is the thread where our broader interest in spatial intelligence and our multi-modal LLM work converge.
Selected references
- SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities (Chen et al., CVPR 2024) — https://arxiv.org/abs/2401.12168
- SpatialRGPT: Grounded Spatial Reasoning in Vision-Language Models (Cheng et al., NeurIPS 2024) — https://arxiv.org/abs/2406.01584
- Grounded 3D-LLM with Referent Tokens (Chen et al., arXiv 2024) — https://arxiv.org/abs/2405.10370
- SceneVerse: Scaling 3D Vision-Language Learning for Grounded Scene Understanding (Jia et al., ECCV 2024) — https://arxiv.org/abs/2401.09340
- An Embodied Generalist Agent in 3D World (LEO) (Huang et al., ICML 2024) — https://arxiv.org/abs/2311.12871
Jongmin Lee
Assistant Professor of Computer Science Engineering
My research focuses on computer vision and machine learning, with interests in visual geometry, 3D vision, and spatial reasoning with multi-modal LLMs. I explore applications in autonomous systems, AR/VR, robotics, and physical AI.