Multi-Modal LLMs & 3D Visual Foundation Model
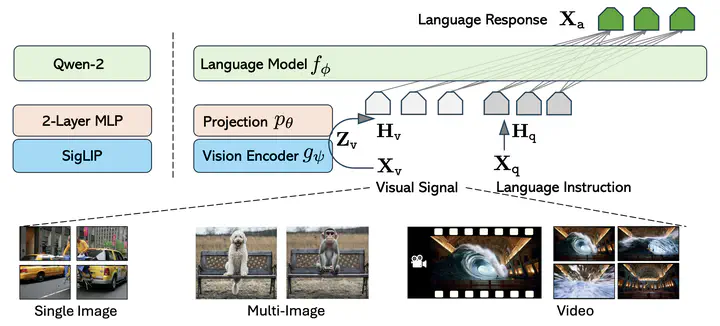 Image credit: LLaVA
Image credit: LLaVAAbstract: My research on multi-modal large language models (LLMs) explores how visual and textual information can be integrated to build powerful visual foundation models, and its’ applications. I focus on post-training methods such as supervised fine-tuning and reinforcement learning with human or preference feedback, as well as representation learning techniques including self-supervision and geometric inductive biases. These models aim to enhance visual perception and reasoning capabilities across diverse tasks such as document understanding, chart and diagram reasoning, and video summarization. By bridging vision and language, I seek to create general-purpose systems that can adapt flexibly to real-world applications.
Research Idea
Multi-Modal LLMs and its’ applications
In this line of research, we aim to develop multi-modal large language models (LLMs) that integrate visual perception with linguistic reasoning, forming the foundation of next-generation vision–language systems. While recent multimodal foundation models (e.g., CLIP, LLaVA, GPT-4V) excel at aligning visual inputs with text, they often lack structural and geometric awareness, limiting their ability to perform fine-grained reasoning about spatial relations and 3D consistency.
To overcome this gap, our research introduces representation learning techniques such as self-supervision, invariance, and equivariance into multi-modal training pipelines. We also explore post-training strategies, including supervised fine-tuning and reinforcement learning with human/preference feedback, to adapt these models for domain-specific perception tasks.
Relavant Papers:
LLaVA-OV: https://llava-vl.github.io/blog/2024-08-05-llava-onevision/
Qwen-VL: https://github.com/QwenLM/Qwen2.5-VL
Molmo (Pixmo): https://github.com/allenai/molmo
Cropper – Vision‑Language Model for Image Cropping through In‑Context Learning, Lee et al., CVPR 2025
Open-Qwen2VL- Compute-Efficient Pre-Training of Fully-Open Multimodal LLMs on Academic Resources (Wang et al., 2025. 04. UCSB)
Reasoning with DPO/GRPO
In addition, I am exploring reasoning-focused post-training methods such as Direct Preference Optimization (DPO) and Group Relative Preference Optimization (GRPO). Starting from the recent line of research exemplified by DeepSeek-R1, I investigate how such preference- and reasoning-oriented training strategies can be effectively transferred into vision–language models (VLMs). The goal is to enhance their step-by-step reasoning ability, improve factual alignment, and explore scalable extensions that combine multimodal perception with robust reasoning.
Visual-RFT: Visual Reinforcement Fine-Tuning, Liu et al., ICCV 2025, : https://github.com/Liuziyu77/Visual-RFT
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models, Huang et al., 2025 03.
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, DeepSeek, 2025. 03.
A Sober Look at Progress in Language Model Reasoning: Pitfalls and Paths to Reproducibility (2025. 04.)
Towards reasoning era: A survey of long chain-of-thought for reasoning large language models (2025. 03.)
Insight-V: Exploring Long-Chain Visual Reasoning with Multimodal Large Language Models (Dong et al., CVPR 2025 highlight; NTU, Tencent)
Critic-V: VLM Critics Help Catch VLM Errors in Multimodal Reasoning (Zhang et al., CVPR 2025; Fudan/Sanghai U)
VISCO: Benchmarking Fine-Grained Critique and Correction Towards Self-Improvement in Visual Reasoning (Wu et al., CVPR 2025; UCLA)
3D Foundation Models
In parallel, we explore the emerging field of 3D foundation models, which aim to learn structure-aware representations of the physical world beyond 2D semantics. Inspired by recent breakthroughs such as CROCO (Cross-View Completion Pre-training), DUSt3R (dense unsupervised stereo/3D reconstruction), and VGGT (Vision Geometry Grounded Transformer), we investigate how large-scale pretraining with geometric priors can support:
- Robust visual correspondence and camera/object pose estimation
- Multi-view consistency and 3D reconstruction
Relavant Papers:
Jongmin Lee
Assistant Professor of Computer Science Engineering
My research focuses on computer vision and machine learning, with interests in visual geometry, 3D vision, and spatial reasoning with multi-modal LLMs. I explore applications in autonomous systems, AR/VR, robotics, and physical AI.