Computer Vision & Visual Geometry
Abstract
Our research asks how a machine can recover the geometry of the physical world from nothing more than a handful of 2D images. Despite the recent leap in visual recognition, today’s models still stumble when scenes shift across viewpoints, when objects rotate, or when scale, occlusion, and clutter break the assumptions baked into pretraining. We build vision systems that fuse classical multi-view geometry with modern representation learning, treating correspondence, pose estimation, multi-view reasoning, 3D reconstruction, and equivariance as five faces of the same underlying problem. Our long-term goal is a geometrically grounded perception stack that any downstream system, whether a robot, an AR headset, an autonomous vehicle, or an embodied agent, can trust to localise itself, understand object pose, and reconstruct unseen geometry from sparse views.
Research Idea
A single photograph is a flattened projection of a much richer 3D world. Our group is interested in the inverse problem: given one, a few, or a stream of 2D images, how do we recover where things are, how they are oriented, how the scene is structured, and how it would look from a viewpoint we never saw? We treat this as a single thread of research with five strongly coupled axes — correspondence, pose, multi-view geometry, reconstruction, and equivariance — and we are actively looking for students and collaborators who want to push any one of them.
Correspondence — Matching pixels, keypoints, and semantics
Almost every geometric vision pipeline begins by deciding which pixel in image A corresponds to which pixel in image B. We are interested in correspondence at every level: sparse keypoints under wide-baseline change, dense pixel flows across moving scenes, and semantic correspondences that link parts of one object to the same parts of a different instance.
A particular obsession of ours is correspondence that survives when the visual world changes underneath the model — different lighting, different style, different identity, different viewpoint. We explore how features from large pretrained backbones (DINO, Stable Diffusion, multi-view transformers) can be re-shaped into representations that are both semantically meaningful and geometrically reliable, and how matching can be grounded in 3D rather than treated as a purely 2D affinity problem.
Selected references
- RoMa: Robust Dense Feature Matching (Edstedt et al., CVPR 2024) — https://arxiv.org/abs/2305.15404
- Grounding Image Matching in 3D with MASt3R (Leroy et al., ECCV 2024) — https://arxiv.org/abs/2406.09756
- A Tale of Two Features: Stable Diffusion Complements DINO for Zero-Shot Semantic Correspondence (Zhang et al., NeurIPS 2023) — https://arxiv.org/abs/2305.15347
- Emergent Correspondence from Image Diffusion (Tang et al., NeurIPS 2023) — https://arxiv.org/abs/2306.03881
- Mind the Gap: Aligning Vision Foundation Models to Image Feature Matching (Sun et al., 2024) — https://arxiv.org/abs/2407.10073
Pose — Where is the camera, and where is the object?
Pose is the bridge between a pixel and a 3D world. We work on both sides of it: camera pose, where we estimate the 6-DoF position and orientation of the device that took the picture, and object pose, where we estimate the rotation and translation of an object in the scene. The interesting regime, and the one we focus on, is when classical assumptions break — extreme rotations, single-view inputs, novel objects without CAD models, or scenes where calibration is unknown.
Two threads especially excite us. First, pose from a single image, where we have to lean on monocular priors, learned scene statistics, and uncertainty estimation rather than triangulation. Second, pose for objects we have never seen before, where the model has to abstract over category and shape and still produce a consistent rotation.
Selected references
- FoundationPose: Unified 6D Pose Estimation and Tracking of Novel Objects (Wen et al., CVPR 2024 Highlight) — https://arxiv.org/abs/2312.08344
- Extreme Rotation Estimation in the Wild (Bezalel et al., CVPR 2025) — https://arxiv.org/abs/2411.07096
- GeoCalib: Learning Single-Image Calibration with Geometric Optimization (Veicht et al., ECCV 2024) — https://arxiv.org/abs/2409.06704
- U-ARE-ME: Uncertainty-Aware Rotation Estimation in Manhattan Environments (Singh et al., 2024) — https://arxiv.org/abs/2403.15583
- Can Generative Video Models Help Pose Estimation? (Cai et al., CVPR 2025) — https://arxiv.org/abs/2407.17738
Geometry — Multi-view reasoning and optical flow
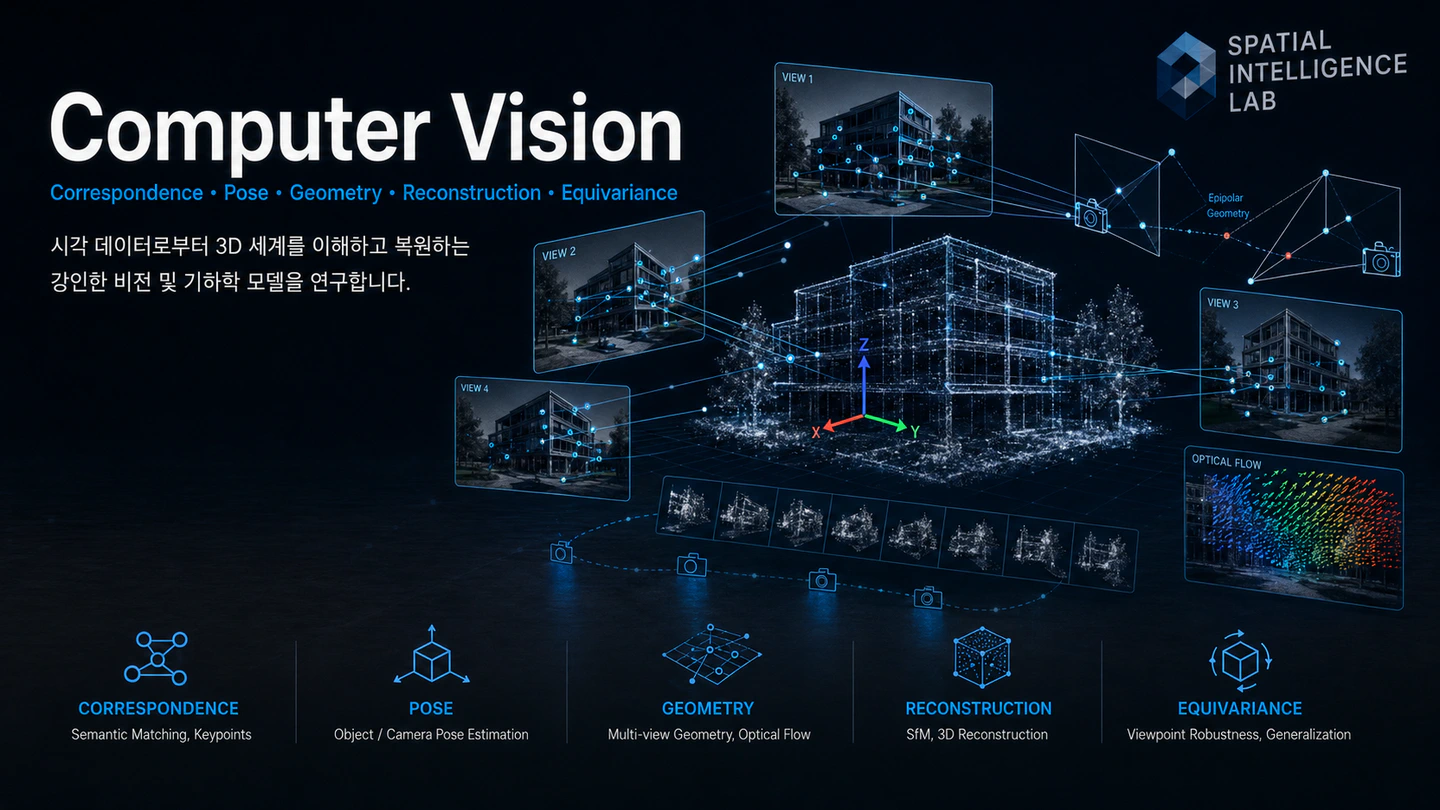
When multiple views of the same scene are available, the geometric relationships between them are an extraordinarily strong signal. We study how to extract and exploit that signal: epipolar structure, dense optical flow, long-range point tracking through video, and the geometry that ties them together. The image on this page captures the spirit — multiple cameras observing one structure, with the flow field and the axes telling a coherent story about motion and viewpoint.
We are particularly drawn to settings where geometry and learning have to cooperate: a learned flow estimator constrained by epipolar consistency, a tracker that respects rigidity, or a multi-view backbone that produces features already aware of the camera geometry. The hope is to design pipelines that are not just accurate but also interpretable in the geometric sense.
Selected references
- SEA-RAFT: Simple, Efficient, Accurate RAFT for Optical Flow (Wang et al., ECCV 2024 Oral) — https://arxiv.org/abs/2405.14793
- CoTracker3: Simpler and Better Point Tracking by Pseudo-Labelling Real Videos (Karaev et al., 2024) — https://arxiv.org/abs/2410.11831
- Coarse Correspondences Boost Spatial-Temporal Reasoning in Multimodal Language Model (Liu et al., CVPR 2025) — https://arxiv.org/abs/2408.00754
- Bridging Viewpoint Gaps: Geometric Reasoning Boosts Semantic Correspondence (Qian et al., CVPR 2025) — https://arxiv.org/abs/2503.18060
Reconstruction — From SfM to feed-forward 3D
How do we go from a pile of images to a usable 3D model? Classical Structure-from-Motion (SfM) answers this with feature matching, bundle adjustment, and triangulation; recent feed-forward transformers answer it by regressing geometry directly from pixels in a single pass. We work on both ends of this spectrum and on the bridges between them.
We are especially interested in robust reconstruction in the wild — internet photo collections, low-overlap captures, calibration-free input, and scenes where monocular priors must compensate for the absence of multi-view evidence. The wireframe scaffolding in the figure above is meant to evoke exactly this: a coherent 3D model emerging from imperfect, partial, multi-view observations.
Selected references
- DUSt3R: Geometric 3D Vision Made Easy (Wang et al., CVPR 2024) — https://arxiv.org/abs/2312.14132
- VGGT: Visual Geometry Grounded Transformer (Wang et al., CVPR 2025 Best Paper) — https://arxiv.org/abs/2503.11651
- MP-SfM: Monocular Surface Priors for Robust Structure-from-Motion (Sarlin et al., 2025) — https://arxiv.org/abs/2504.20040
- MASt3R-SfM: A Fully-Integrated Solution for Unconstrained Structure-from-Motion (Duisterhof et al., 2024) — https://arxiv.org/abs/2409.19152
Equivariance — Viewpoint robustness and generalisation
A recurring failure mode of modern vision systems is that they are fragile to viewpoint. Rotate an object, tilt the camera, lift the scene off its canonical pose, and accuracy collapses. We believe a principled answer lies in equivariant representation learning: design the network so that transformations of the input produce predictable, structured transformations of the features, instead of relearning them from data.
We explore equivariance at several scales — rotation-equivariant features for visual correspondence, SO(3)-equivariant heads for pose regression, and “equivariant adapters” that retrofit large pretrained backbones (DINO, CLIP, DUSt3R-style foundations) so that they inherit viewpoint robustness without retraining from scratch. The deeper question we are chasing: can equivariance act as an inductive prior that replaces large amounts of augmentation and 3D supervision?
Selected references
- e3nn: Euclidean Neural Networks (Geiger & Smidt, 2022) — https://arxiv.org/abs/2207.09453
- Equivariant Adaptation of Large Pretrained Models (Mondal et al., NeurIPS 2023) — https://arxiv.org/abs/2310.01647
- ORIGEN: Zero-Shot 3D Orientation Grounding in Text-to-Image Generation (Min et al., 2025) — https://arxiv.org/abs/2503.22194
- Vision Foundation Model Enables Generalizable Object Pose Estimation (Cai et al., NeurIPS 2024) — https://arxiv.org/abs/2409.15727
- SO(3)-Equivariant Representation Learning in 2D Images (Granberry et al., NeurIPS 2023 Workshop) — https://openreview.net/forum?id=qDVCBKezNa
Looking for collaborators
If any of the five threads above resonates — whether you come from classical geometry, deep learning, robotics, or applied math — we would love to talk. We are particularly interested in students who want to ground large vision foundation models in real 3D geometry, and in external collaborators working on robotics, AR/VR, or embodied AI where reliable spatial perception is the bottleneck.
Jongmin Lee
Assistant Professor of Computer Science Engineering
My research focuses on computer vision and machine learning, with interests in visual geometry, 3D vision, and spatial reasoning with multi-modal LLMs. I explore applications in autonomous systems, AR/VR, robotics, and physical AI.