Abstract
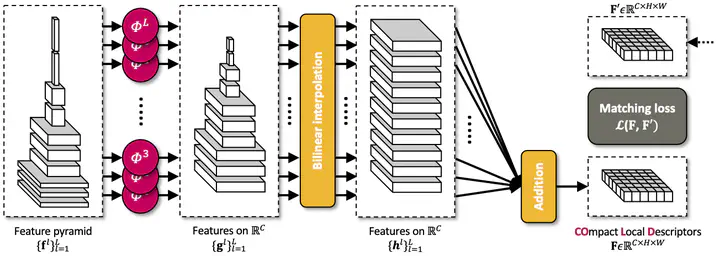
Extracting local descriptors or features is an essential step in solving image matching problems. Recent methods in the literature mainly focus on extracting effective descriptors, without much attention to the size of the descriptors. In this work, we study how to learn a compact yet effective local descriptor. The proposed method distills multiple intermediate features of a pretrained convolutional neural network to encode different levels of visual information from local textures to non-local semantics, resulting in local descriptors with a designated dimension. Experiments on standard benchmarks for semantic correspondence show that it achieves significantly improved performance over existing models, with up to a 100 times smaller size of descriptors. Furthermore, while trained on a small-sized dataset for semantic correspondence, the proposed method also generalizes well to other image matching tasks, performing comparable result to the state of the art on wide-baseline matching and visual localization benchmarks.
Jongmin Lee
Assistant Professor of Computer Science Engineering
My research focuses on computer vision and machine learning, with interests in visual geometry, 3D vision, and spatial reasoning with multi-modal LLMs. I explore applications in autonomous systems, AR/VR, robotics, and physical AI.