SetPieceRAG: Domain-Specific RAG for Knowledge-Intensive Soccer VQA with Large Language Models
Abstract
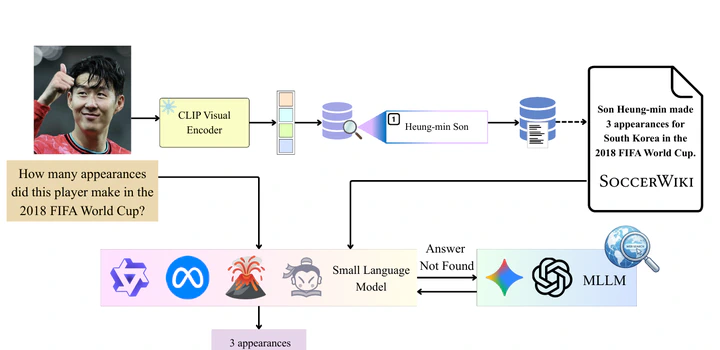
Visual Question Answering (VQA) in the soccer domain extends beyond simple visual queries, serving as a crucial step toward comprehensive sports video understanding. To address the limitations of existing methodologies, we propose a novel domain-specific Retrieval-Augmented Generation (RAG) framework tailored for soccer. Beyond the core RAG mechanism, we introduce task-specific adaptations to address the diverse soccer VQA tasks, including LLM ensembling, LoRA-based domain fine-tuning, super-resolution preprocessing, and object-centric analysis via SAHI. To tackle the knowledge-intensive queries that are notoriously challenging in VQA, our approach integrates vision-language tools like CLIP with external knowledge sources, including a domain-specific corpus (SoccerWiki) and the web search capabilities of Multimodal Large Language Models (MLLMs). This integration effectively provides the non-parametric and long-tail knowledge inherently lacking in both Large and Small Language Models (LLMs/SLMs). By precisely retrieving and injecting requisite external knowledge, we demonstrate significantly enhanced retrieval performance and accurate answer generation on the challenging SoccerNet VQA benchmark.
Jongmin Lee
Assistant Professor of Computer Science Engineering
My research focuses on computer vision and machine learning, with interests in visual geometry, 3D vision, and spatial reasoning with multi-modal LLMs. I explore applications in autonomous systems, AR/VR, robotics, and physical AI.