Spatial Intelligence Lab.
Spatial Intelligence Lab.
Tour
News
People
Research
Publications
Contact
Paper-Conference
Exaone 4.0 VL: Vision-Language Foundation Model for Enterprise AI Agent
Exaone-4.0-VL, a 32B multi-modal foundation model, achieves SOTA across vision-language benchmarks and empowers enterprise AI agent applications.
Jongmin Lee
,
LG AI Research
Video
Announcement Video
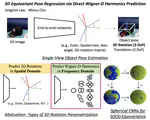
3D Equivariant Pose Regression via Direct Wigner-D Harmonics Prediction
SO(3)-equivariant pose harmonics enable consistent single-image 3D orientation estimation by directly regressing Wigner-D coefficients in the frequency domain, overcoming discontinuities in spatial parameterizations.
Jongmin Lee
,
Minsu Cho
PDF
Cite
Code
Poster
Video
Learning Rotation-Equivariant Features for Visual Correspondence
This work proposes a self-supervised framework using group-equivariant CNNs and a novel group-aligning technique to learn discriminative, rotation-invariant local descriptors for robust image matching and pose estimation.
Jongmin Lee
,
Byungjin Kim
,
Seungwook Kim
,
Minsu Cho
PDF
Cite
Code
Self-Supervised Equivariant Learning for Oriented Keypoint Detection
This work introduces a self-supervised framework with rotation-equivariant CNNs and a dense orientation alignment loss to detect robust oriented keypoints, achieving state-of-the-art results in image matching and camera pose estimation.
Jongmin Lee
,
Byungjin Kim
,
Minsu Cho
PDF
Cite
Code
Self-supervised Learning of Image Scale and Orientation Estimation
This work presents a self-supervised histogram alignment framework for estimating scale and orientation of image patches, achieving superior pose estimation and boosting image matching and 6-DoF camera pose estimation.
Jongmin Lee
,
Yoonwoo Jeong
,
Minsu Cho
PDF
Cite
Code
Learning to Distill Convolutional Features Into Compact Local Descriptors
This work proposes a feature distillation framework that learns compact yet effective local descriptors by combining multi-level CNN features, achieving up to 100× smaller size while maintaining state-of-the-art performance across image matching tasks.
Jongmin Lee
,
Yoonwoo Jeong
,
Seungwook Kim
,
Juhong Min
,
Minsu Cho
PDF
Cite
Hyperpixel Flow: Semantic Correspondence with Multi-layer Neural Features
This work proposes Hyperpixel Flow, a real-time matching algorithm using hyperpixels that combine multi-level CNN features with Hough voting, achieving state-of-the-art correspondence on three benchmarks and the large-scale SPair-71k dataset.
Juhong Min
,
Jongmin Lee
,
Jean Ponce
,
Minsu Cho
PDF
Cite
Code
Dataset
Learning to Compose Hypercolumns for Visual Correspondence
This work introduces Dynamic Hyperpixel Flow, a method that adaptively composes hypercolumn features from relevant CNN layers conditioned on image pairs, achieving state-of-the-art semantic correspondence with improved efficiency.
Juhong Min
,
Jongmin Lee
,
Jean Ponce
,
Minsu Cho
PDF
Cite
Code
Attentive Semantic Alignment with Offset-Aware Correlation Kernels
This work introduces an attentive semantic alignment method with an offset-aware correlation kernel that filters out distractors and captures local transformations, achieving state-of-the-art performance in semantic correspondence.
Paul Hongsuck Seo
,
Jongmin Lee
,
Deunsol Jung
,
Bohyung Han
,
Minsu Cho
PDF
Cite
Code
Cite
×